Briefings in Bioinformatics:为肿瘤精准诊断预测提供全新标志物体系,上科大刘雪松团队揭示新型肿瘤基因组DNA拷贝数变异模式
时间:2023-02-24 10:16:42 热度:37.1℃ 作者:网络
肿瘤是由体细胞基因组DNA变异所驱动产生的复杂疾病,系统研究基因组DNA变异的内在规律有助于从根本上理解肿瘤的发病原因,进而设计更有效的精准诊断和治疗策略。依据体细胞DNA变异的性质和规模,肿瘤基因组DNA变异的类型可分为两大类,其一是简单变异,如单个碱基替换(single base substitution,SBS)、小片段插入删除(small indels);其二是复杂变异,拷贝数变异(copy number alteration,CNA)是基因组DNA复杂变异的典型代表。拷贝数变异在肿瘤演化发展过程中发挥着非常关键的驱动作用。
研究表明,很多类型的单个碱基替换(SBS)在形态正常的组织细胞里面常有发生,然而拷贝数变异(CNA)的发生局限在肿瘤细胞中,提示了基因组DNA拷贝数变异的发生是肿瘤细胞区别于正常体细胞的关键分水岭。然而CNA的复杂程度远高于单个碱基突变,其变异背后的特征寻找和驱动因素研究也更加复杂,一系列相关的关键科学问题依然没有解决,如CNA特征分类、CNA模式识别、CNA模式与肿瘤精准诊断预测关系等。
2012年开始有研究依据单点变异左右碱基背景将肿瘤基因组突变进行特征分解,最后总结出大约30多种DNA单点突变的模式(mutational signature)。这类分析让我们从表面上杂乱无章的单点突变背后,看到驱动单点突变产生的因素或分子事件。如吸烟、衰老分别在基因组DNA上面留下不一样且可识别的单点突变模式。单点变异是相对而言比较简单的基因组DNA变异,拷贝数变异(CNA)的变异特征及其模式研究目前还相当匮乏,这大大阻碍了CNA信息在肿瘤精准诊断预测中的应用。
近日,上海科技大学生命科学与技术学院刘雪松课题组在 Briefing in Bioinformatics 期刊发表了题为:The repertoire of copy number alteration signatures in human cancer 的研究论文。
该研究针对肿瘤基因组拷贝数变异(CNA)数据,建立了适应原始数据来源广、已知拷贝数变异机制非依赖的、泛癌种适用的CNA模式识别与定量方法,并在不同数据中验证了该方法在癌症分型预后中的实际应用价值。

研究团队利用2778个公共数据库PCAWG(32种癌症类型)全基因组测序数据,构建了拷贝数变异模式识别方法,进一步运用10851个TCGA样本(33种癌症类型)SNP芯片数据验证了该拷贝数变异模式识别方法的稳定性及可靠性。
该研究提出了一种创新的拷贝数片段分类方法并应用于拷贝数变异模式识别,该分类方法考虑了拷贝数片段的如下特征:拷贝数片段长度、片段绝对拷贝数、片段杂合性状态、片段前后背景形态信息。考虑到真实世界数据的实际情况,最终获得176个CNA类别(图1)。相比现有的CNA模式识别方法,该方法能够提供更为细致的拷贝数片段信息,为深入理解CNA规律模式、发生驱动因素解读提供了基础。
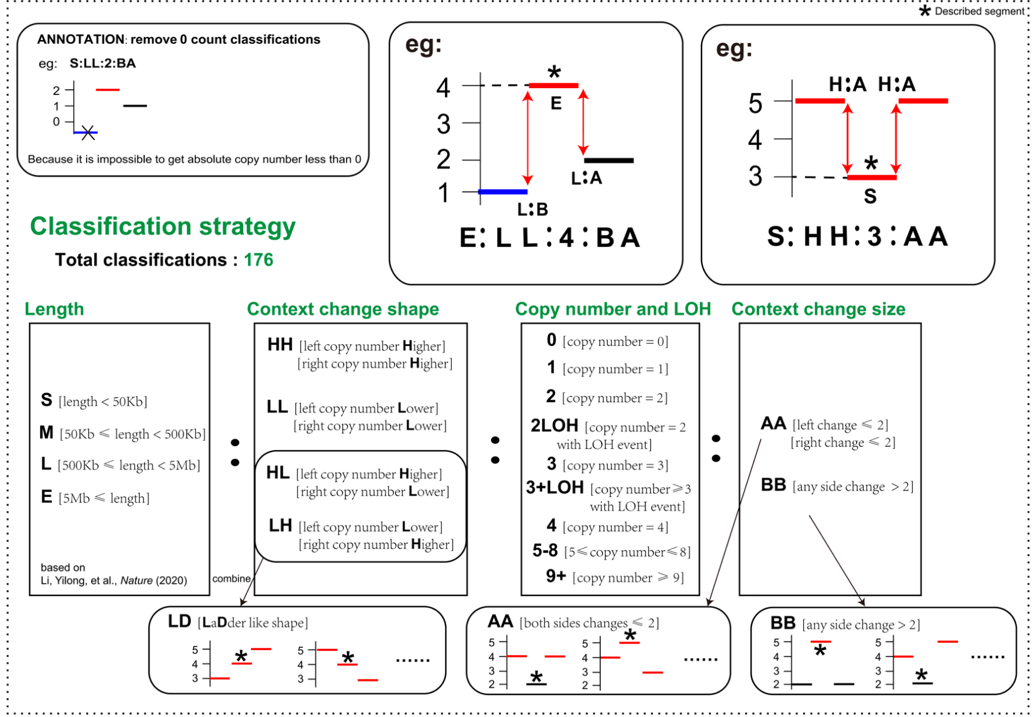
图1:拷贝数片段数据分类策略
此外,该研究团队还探究了该CNA模式识别方法在肿瘤精准预后预测中的应用,研究发现部分CNA模式的强弱与肿瘤的预后密切相关(图2A、C),这种相关性在不同来源的数据中稳定存在(图2B),提示CNA模式在肿瘤精准预后诊断中具有重要的应用前景。
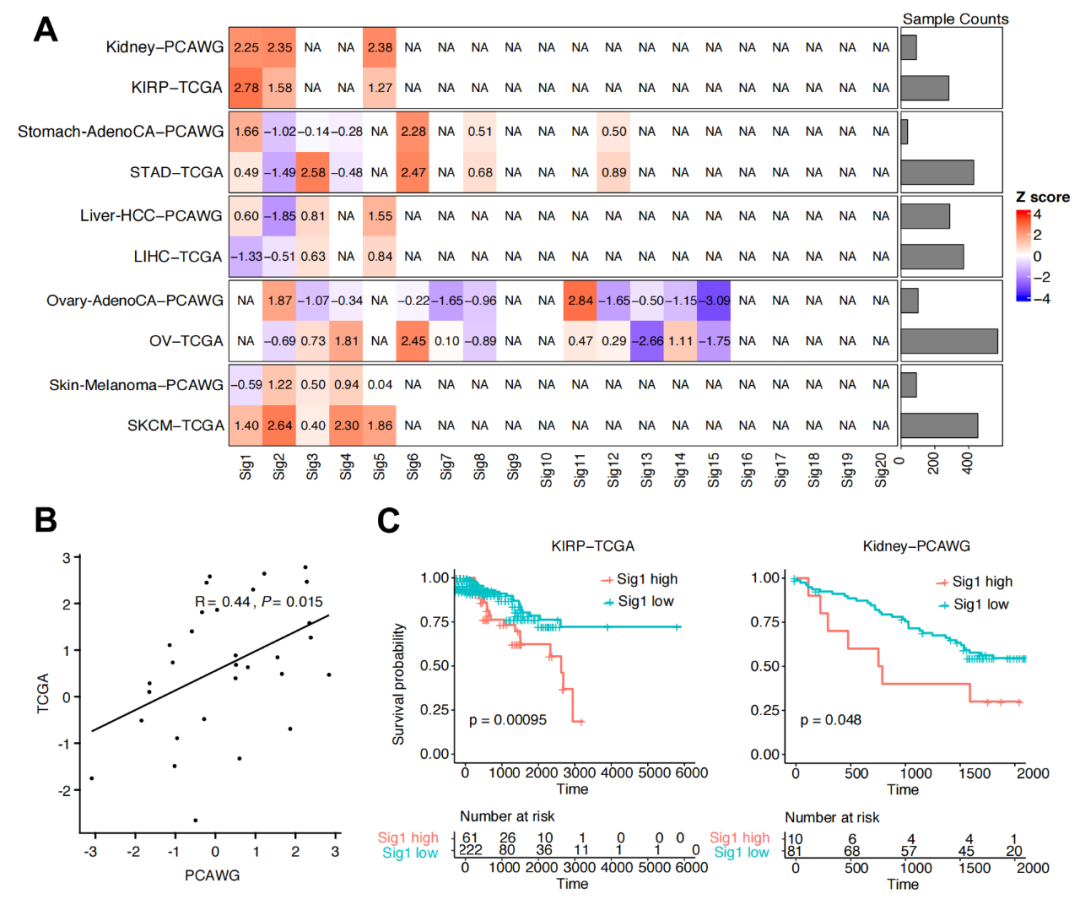
图2:拷贝数变异模式与癌症患者预后的关系
考虑到CNA检测方式的简便性和多样性,如低深度全基因组测序技术等等,具有低成本高效率的优势,与以往简单描述基因组DNA的拷贝数局部删失和扩增的信息不同,该方法提供了CNA在整体上的变异模式。结合了CNA特征模式与人工智能的“拷贝数指纹”预计将为肿瘤精准诊断预测带来全新的标志物体系。
总而言之,该研究开发了新型的CNA模式定量方法,发现了全新的肿瘤基因组CNA模式,不仅为深入研究肿瘤发生发展的基础,尤其是肿瘤基因组DNA变异的特征模式及背后驱动因素,提供了基础,而且为肿瘤的精准诊断预测提供全新的标志物体系。

